多语言全文搜索
October 25, 2020
百度一下,你就知道;谷歌一下,你知道的太多了。
在工作中的一个项目里,我在文档系统 Docusaurus v2 之上实现了一个支持多语言的(针对中文文档有特别优化的)、离线/本地的全文搜索插件,托管在 GitHub 上:https://github.com/easyops-cn/docusaurus-search-local 。
在信息化时代,我们的日常生活总是离不开搜索,在浏览器中搜索电影、搜索工作遇到的问题,在通讯软件中搜索联系人、聊天记录等等。即使只输入简单的一两个词,我们也能迅速得到想要的信息,当然还有一些时候我们可能只得到了不相关的信息,或者在搜索结果中翻遍数十条信息才能找到真正有用的那条。
看似非常简单的搜索功能,用户获得的体验却可能有显著的差别,背后的原因是什么?在实现这个搜索插件的过程中,我得以略窥一斑。
我们先从几个简单的例子着手,来看看全文搜索是如何工作的。
例一,搜索“鸡鸭鹅”,可以匹配 “我家养了一只鸡,两只鸭,三只鹅” 吗?答案是可以,因为鸡、鸭、鹅作为独立的词都出现在了文档中。
例二,搜索“数学家”,可以匹配 “在数字化的今天,我们在家也能学习” 吗?不能,虽然三个字都出现了,但“数学家”才是一个完整词语,它没有得到匹配。
例三,搜索 “wolf”,可以匹配 “Wolves are never alone” 吗?虽然没有完整的 “wolf” 在文档中,但 “wolf” 的复数形式 “wolves” 出现了,它应该得到匹配。
例四,搜索 “write a test” ,对于以下两篇文档如何匹配:
- “Let's talk about how to write tests. bla bla...”
- “There is a test tube in the laboratory. bla bla...”
答案是匹配第一篇,虽然两篇文档都只各自匹配了其中两个关键词 “write, test” 或 “a, test” ,但单词 “a” 通常不具备搜索的意义,一般会在搜索中忽略它。
例五,假设在一个测试库的文档站点中包含以下几篇文档,搜索 “integration test” 时:
- “Tests are essential, you should introduce integration tests.”
- “Integrations build your confidence. Here is how to do integration tests.”
- “This test library bla bla... And this test library bla bla...”
- “You can test in this way... You can test in that way...”
不难看出搜索结果应该是第一、二篇,只有它们同时提及了要搜索的两个关键词。那么谁应该出现在搜索结果的第一位呢?前者包含了 1x “integration” + 2x “test”,后者出现了 2x “integration” + 1x “test”,看起来难分伯仲?我们稍后再来讨论。
以上几个例子分别涉及了全文搜索的其中几个要素:
- 标记化(Tokenization);
- 词干提取(Stemming);
- 停用词(Stop Words);
- 相关度(Relevance)。
我们将分别讨论它们。
标记化
标记化是建立索引的第一步,将文本拆分成一个个独立的最小的有意义的单元,这些单元被称为标记(Token)。无论是英语的字母还是现代汉语的单字,通常都不具备独立表达的意义,因此,这里的标记一般来说就是词。
例如 “I have a dream!” 很容易拆分成四个标记:['I', 'have', 'a', 'dream!']。对于由拉丁字母组成单词、单词之间有空格分隔的英语来说,标记化显然是非常容易的,只需按空白符号拆分就好了。
而对于汉语(现代汉语)来说情况就不同了,同样是三个字的“鸡/鸭/鹅”和“数学家”分别拆成了三个和一个标记,同时诸如“发展/中/国家”又要避免错拆成“发展/中国/家”。不过不用担心,已经有很多相对成熟的理论以及造好的轮子可以使用,例如基于结巴中文分词的 Node.js 实现 nodejieba。
标记化后通常还会有一步修整(Trimming),将各个标记中的特殊字符删去,例如 dream! 修整后变为 dream。
词干提取
词干提取是将不同屈折变化或派生的单词归并到相同的词根的过程。例如英语的 “wolves” 可以归并到 “wolf”,而 “fishing”、“fished” 和 “fisher” 则可以都归并到 “fish”。
对于具有屈折语特性的语言(例如英语)来说,词干提取有利于减少索引的标记数量及索引大小,同时提升搜索的灵敏度。
而以分析语为主要特征的现代汉语则基本没有屈折变化,而是以语序表示语法关系,以虚词表示语法功能,例如“了”表示过去式,以“着”表示进行时,以“的”表示属格,等等。这些虚词可以作为停用词而在建立索引时剔除,因此无需进行词干提取。
有趣的事实:上古汉语其实具有屈折语特性[1],例如“吾”多是主格和属格,而“我”则是与格和宾格;“汝”和“尔”,“其”和“之”则是与前者类似的第二、三人称表示。因此上古汉语其实是可以进行词干提取的。
词干提取同样有相对成熟的算法和实现,例如英语有 1980 年就被提出的 The Porter Stemming Algorithm。
停用词
停用词即一些没有实际含义的词,例如英语的 “the”、“it”、“so”,汉语的“了”,“的”,“们”等等。在索引中记录它们或者搜索它们,通常来说跟搜索结果都是不相关的,因此停用词会被剔除而不被录入索引中。
相关度
相关度即各个文档与搜索关键词之间的相关性,相关度决定文档出现在搜索结果列表里的顺序,因此相关度计算是搜索系统中最重要的环节之一。
对于非信息检索专业的人来说,我们只需要了解常见算法的基本原理即可。例如 tf–idf 统计法,它评估一个字词对于一个文档库中的其中一份文档的重要度,该方法认为字词的重要性随着它在该文档中出现的次数成正比增加,但同时会随着它在整个文档库中出现的频率成反比下降。
我们重新回到前文中提到的例子,假设在一个测试库的文档站点中包含以下几篇文档,搜索 “integration test” 时:
- “Tests are essential, you should introduce integration tests.”
- “Integrations build your confidence. Here is how to do integration tests.”
- “This test library bla bla... And this test library bla bla...”
- “You can test in this way... You can test in that way...”
按 tf-idf 统计法,“test” 在整个文档库中高频出现-四篇,而“integration”只在两篇中出现,因此“test”的重要性相对打了折扣,所以出现更多次“integration” 的第二篇文档应该列在搜索结果的前面。
对于普通的文档库搜索,tf-idf 统计法已经足够实用,而对于网页搜索引擎,还会加入更加复杂的基于链接和引用的评级方法,这里不再展开讨论。
精度和灵敏度
精度和灵敏度是评价一个搜索系统优劣的主要指标。精度是指在所有搜索结果中有多少比例的内容是真正相关的,而灵敏度指的是真正相关的内容中有多少比例被列在了搜索结果中。

例如我们常说 “GG 总是能找到我要的内容”主要指的是搜索灵敏度高,而 “BD 总是给我不相干的内容”主要指的是搜索精度低。
好的搜索系统应当同时有出色的精度和灵敏度。灵敏度高而精度低的后果是,虽然用户想要的内容都在搜索结果中,但其中还掺杂了大量的无用内容,需要用户自行分辨。精度高而灵敏度低的后果是,虽然搜索结果中基本都是相关的内容,但同时也有很多其它相关的内容被忽略了。
前文提到的“鸡/鸭/鹅”的拆分有助于提升搜索灵敏度,而如果将“数/学/家”也进行拆分,则会降低搜索精度。
“我有一个绝妙的 idea,只差一个程序员了。”
有了理论的加持,我们可以动手实践了。在一个静态文档系统中实现本地搜索主要包含两项工作:
- 在构建时为所有文档建立索引;
- 在前端界面实现搜索交互。
建立索引
站在蓬勃发展的前端社区化这一巨人的肩膀上,我们得以非常轻松的启动这个搜索插件的开发。
首先是对文档文本内容的扫描,使用 cheerio 可以方便地实现对 html 文件的结构化文本信息的提取,具体实现与本文主题关系不大,不再展开讨论。
lunr.js 是一个轻量而实用的搜索库,它提供了将索引文件序列化的能力,并允许在 js 中重新加载索引文件,这使得我们的本地搜索成为了可能。
另一方面,它结合 lunr-languages 可以开箱即用地实现包括英语在内的大多数主流印欧语系语言的索引建立,并已经集成了前文提到的标记化、词干提取、停用词和相关度计算等能力。唯一问题是目前没有支持汉语,不过有足够的接口可以让我们自己去实现汉语的支持。
首先是标记化,前面提到汉语有专用的分词方法,我们可以先单独识别出所有的连续汉字,使用以下正则表达式:
// https://zhuanlan.zhihu.com/p/33335629
const HANZI = /\p{Unified_Ideograph}+/u再使用 nodejieba 对这些连续汉字进行分词。注意建立索引时的分词是可以有冗余的,例如“研究生命科学”,可以同时拆成两组标记:“研究/生命科学”和“研究/生命/科学”,这样有助于提高搜索灵敏度。对于英语同样可以存储冗余标记,例如针对技术文档特性,可以拆分 snake_case 字符串,诸如 “api_gateway” 也可以存储两组标记 “api_gateway” 和 “api/gateway”,这样当用户搜索 “api gateway” 时也能搜索到该文档。
剩下的工作包括补充一些汉语停用词,在相关度方面,lunr.js 已经集成了和 tf-idf 统计法非常类似的 BM25 算法。
根据文档数量和内容的多少,序列化后的索引文件在 GZIP 压缩后也可以到达数百 KB,这会是一笔不小的开销,因此我们可以为该索引文件加上长缓存策略,同时计算出索引内容的 hash 值,在请求该索引文件时带上这个参数,以便在索引更新时自动地使缓存失效。
搜索交互
搜索词分词
建立索引时我们已经对文档内容进行了标记化分词,那么在前端页面中、用户输入的搜索关键词还需要再进行分词吗?回顾前面“鸡鸭鹅”和“数学家”的例子,就知道搜索词也需要分词。
那么问题来了,作为一个静态文档站点,没有服务端程序,如何在前端进行汉语的分词呢?注意我们在建立索引时使用的 nodejieba 虽然是 Node.js 程序,但实际底层调用的是 C++,因此无法在浏览器中使用。当然 GitHub 上也有一些可以在浏览器中使用的中文文词 JS 库,但它们通常体积较大,或分词准确性不足,另外如果在建立索引和执行搜索时分别使用了不同的分词方法,可能导致分词不一致进而导致无法正确完成搜索。
我们注意建立索引时已经完成分词,索引文件中已经包含文档库所有文档的所有词语的集合,这个集合就是一个现成的词典,而文档库中能得到搜索结果的关键词肯定也只能出现在这个词典中,因此我们在前端页面中完全可以基于这个词典进行分词。
相关度优化
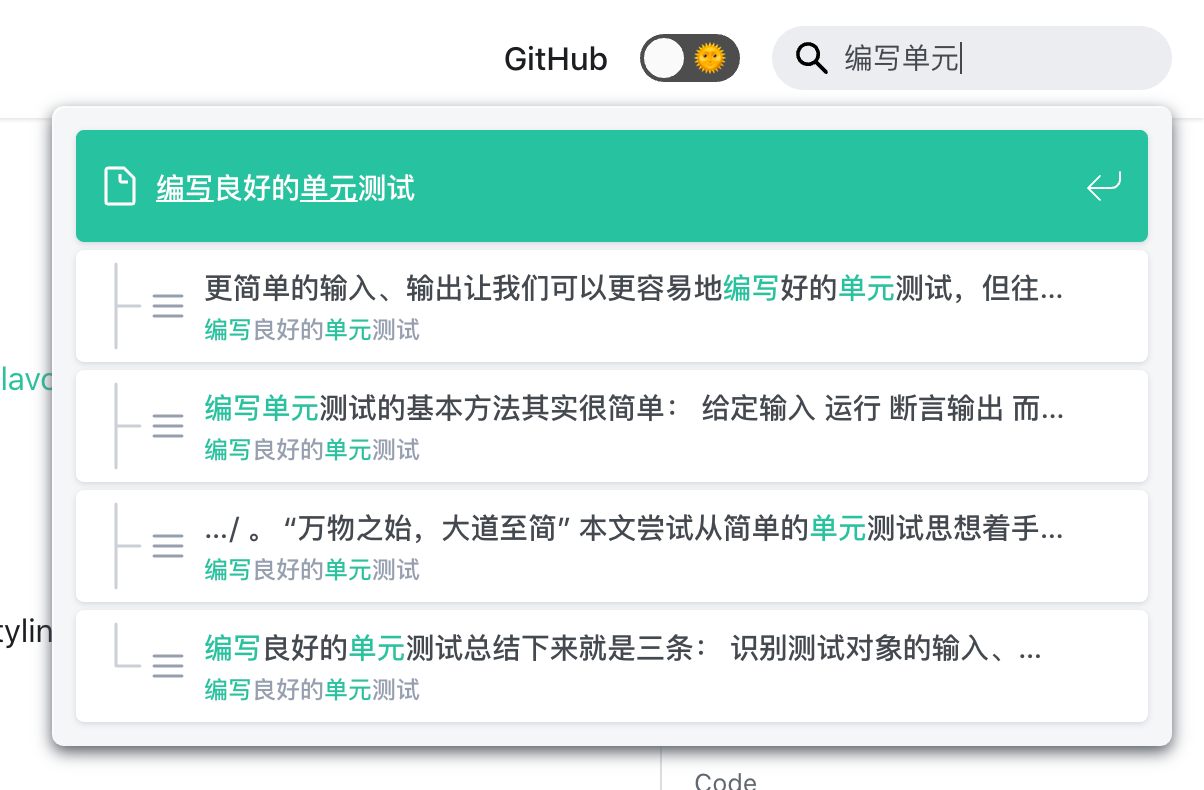
在文档中,不同部分的重要性是不同的,例如搜索 “integration test” 时,页面标题中就包含这两个关键词的文档应出现在前面,在正文内容中匹配的文档应出现在后面,而在次级标题中匹配的应出现在中间。
lunr.js 使用的 BM25 相关度算法没有加入相关的参数,因此在实践中,我们实际上分别为页面标题、次级标题和正文内容建立了索引,执行搜索时依次访问它们,以实现重要性的分级。
模糊匹配
在网页中搜索时,当我们键入了一部分还未完成的搜索词时,我们就能得到非常贴心的搜索词建议,这得益于搜索引擎的自动推荐算法。
前面提到我们的搜索是本地的,当索引文件加载完成后就可以实时搜索,因此我们有办法比前者更进一步:当用户只键入了部分搜索词时,我们就可以提前将可能的搜索结果列出来。只需将分词后的最后一个关键词加上末尾通配符即可。
“程序写好了,只差一个美工了。”